演讲中黄仁勋不仅提及NVIDIA的AI新品趋势、未来的合作伙伴,并且表示,台湾是电脑生态圈的中心,NVIDIA将在台设置办公室,地点就在士林北投。

NVIDIA 30年来有着戏剧化的成长,从原本是为了创造全新运算平台的晶片公司,2006年创造了Cuda(Compute Unified Device Architecture),2016年,我们发现新的演算方法来临,我2006年在GTC提及时没有人知道我在说什么,我捐了一台给当时的一家非营利组织,那家公司叫做OpenAI。而那开启了AI革命。
电脑不再只是一台PC
数年后我们发现,这种软体运行方法(现在叫做AI),跟以往我们所知道的方法截然不同。以往许多应用程式只需少数处理器,在一个大型的资料中心我们叫它Hyperscale(超大规模),而这种创新的方式则是需要大量的处理器同时运作,为上百万的人们服务。而这个资料库的架构完全不同。我们发现有两种网络,一是North-South traffic(南北向流量),你还是必须要控管储存与计画,也必须外连。但更重要的则是East-West traffic(东西向流量),电脑们彼此沟通去试着解决问题。我们认为最好最棒的东西向网路公司,这家公司与NVIDIA 也非常亲近,叫做Mellanox,因此我们5年前收购了他们。我之前也提过,这个世代所说的电脑,是指一个完整的资料中心,不再只是一台个人电脑、一台伺服器,而是整个资料中心共同完成一项任务。
NVIDIA在方面的旅程,现在已经被大家熟知。过去三年,大家可以看见概念被塑造出来,而我们开始用不同的视角来看整家公司。

NVIDIA是基础建设公司
历史上绝对没有任何一家科技公司会一口气揭露未来5年的规划蓝图。没有人会告诉你下一步会如何,大家会极端机密。然而我们知道NVIDIA已经不再只是单纯的科技公司,我们是一家基础建设公司。如果你不知道未来的计画,那么你要怎么规划包括土地、建设、能源、电力、经济等等的基础建设?因此我们用非常细节的方式来描绘公司未来的蓝图,细节到全世界的每个人都能够也开创一家资料中心。我们知道我们是一家AI基础建设公司。全世界、任何地区、任何行业都需要基础建设公司。
今日的AI如同工业革命的电力
而什么是基础建设?有点像是第一次工业革命时大家知道的通用电气、西屋电器、西门子那种公司,让当时的世人知道了电力是最新的科技,也让世界上所有的人都广为建设。多年后,我们这个世代的人发现一种新的基础建设,而这种新的基础建设是非常抽象且难以理解,叫做资讯(Information)。是基础建设的概念,一开始没有人听得懂,而我们后来理解了,那就是。网路无所不在,而且连结所有的事情。如今一项更新的基础建设出现了,这种基础建设奠基于网路和资讯之上,这种基础建设指的是。我知道这听起来好像很不合理,但我保证,十年后你回头来看,你会发现,AI现在已经处处可见,而且事实上我们到处都需要AI。而且全世界每个角落、每家公司、每个行业都需要AI。AI已经是基础建设的一部分,而且是如同网路、电力一样需要工厂,这个工厂就是我们今日正在建构的。

AI工厂化
这不像过去的资料中心,为百万元产业提供资讯与储存空间,支援企业ERP系统和僱员,虽然和这行业中的你我以往提供的概念很类似,但即将发展成截然不同的东西。虽然这个说明不太恰当,但即将演变成:像工厂的概念,你花精力投入,然后产出有价值的东西,这东西我们称为Token。简单来说,未来大家将会讨论的是,公司上一季或上个月产出了多少Token,甚至很快地,我们每小时产出多少Token,就像工厂一样。世界将会变得不一样。
1993年我创办公司时曾经思考公司有多大的商机,我的结论是NVIDIA的商机非常巨大,有三亿元的市场,我们会变得很富有。而当时三亿元的晶片公司,现在即将成长为具有兆元商机的资料中心、一个AI工厂、AI基础建设产业,未来将是以兆元估算的商机,这是我们全力以赴迎接的令人兴奋的未来。
本质上来看,我们正在做的都与几项重要科技有关,当然我很常提到高速运算、AI,但什么是NVIDIA独特之处?是这些技术的整合。而更特别的是,我们称为Cuda-X Libraries的演算法与程式库。我们老是在讲程式库,其实我们似乎是全世界唯一不停提及程式库的科技公司,原因是程式库就是我们的核心,也是我们的起点,我今天也会展示一些新的程式库给你们看。
巨大图像9成由AI推测
你们看到的一切,都是模拟科学技术与AI人工智能,没有艺术创作,都是模拟,只是刚好看起来很美。我身后的萤幕是电脑即时图像技术,并不是拍摄的影片,是由G-force提供,我手中的G-force RTX 5060是来自ASUS,笔电来自MSI,我们将G-force RTX 5060的GPU塞进薄薄的笔电里,这很棒吧!因此让MSI最新的笔电里有了G-force RTX 5060。G-force 让Cuda来到世人眼前,你看见的这个超大影像,每个像素都做了真实的光线追蹤模拟处理。我们怎么可能做到在这么大的影像中以如此大的解析度模拟光线粒子?原因就是AI智能。你看到的像素只有十分之一是由电脑生成的,剩余的十分之九是AI推测的。这看起来很完美,也就是说AI推测的非常完美,这项技术叫做。这花了我们很多年来研发,我们从开始研发AI就着手研发DLSS,所以至少花了十年。而AI彻底革新了电脑图像的进展。G-force将AI带到这个世界,如今AI回来,带给G-force一场革命。G-force RTX 50系列刚完成了最成功的上市,30年电玩史上最快速的上市,这说明了G-force有多厉害。

接下来我们谈谈程式库。简单来说当然所有一切都跟Cuda有关,我们尽可能优化Cuda效能并且普及化,所以安装基础遍布全世界,好让应用程式方便找到Cuda的GPU。当装机量越大,就越多开发商乐于创造程式库,当程式库越多,就会有越多好的应用程式,使用者觉得更好用,他们就会买更多的电脑。越多人买电脑,就会有越多的Cuda,这个良性反馈循环是至关重要的。
然而,高速运算与通用运算不同,通用运算像是写程式,Python、C、C++,让电脑跑得顺畅就行。但这概念无法用在高速运算上,因为如果可以,那就叫做CPU了。高速运算是另外一种逻辑,而通用运算有成千上万的人在做,上兆元的创新,但要如何能做到在一个晶片中只需更动一些小工具,就能让所有的电脑速度变快五十倍甚至一百倍,听起来不可能,所以我们提出的逻辑是,如果所有人都能理解这件事,我们就可以让应用程式变快。
如果你想让所开发的应用程式像光速一样快,99%的运作时间只需佔据5%的程式码,很妙的是,大多数应用程式的运算都来自于很小部分的程式码,我们发现了这件事,所以我们的程式库一一拜访不同应用程式的网域。当然程式库本身导致我们能够串连一个个不同知识网域,来达到加速的目的,但这也打开了我们的市场。我们看见每个不同的领域与市场,科学、医学我们发现将那转换成电脑运算用途是非常重要的。
未来所有电脑都有量子加速器
当通用电脑运算已经发展多年,但为什么没有运用在所有的产业呢?因此是非常重要的。正当世上所有的云端资料库都成为软体定义网路(SDN) ,传统倚赖硬体的资料传输也应该由软体控制,来提升灵活性与可编程性。我们花了六年时间,开发并优化一套全加速的无线接取网路(RAN,Radio Access Network),实现了惊人的效能表现。每兆瓦所能提供的资料传输速率,都是最先进的ASICs(Application-Specific Integrated Circuits)晶片等级,一旦我们能够做到如此顶尖的效能,我们就能加入AI。我们有很棒的合作伙伴,包括 SoftBank、T-Mobile、Indosat、Vodafone 都在进行测试;Nokia、Samsung、Kyocera 与我们合作整个堆叠;Fujitsu 与 Cisco 则专注于系统层面。所以我们今天能将AI应用于5G、6G 通讯系统,就如同我们将AI应用于传统运算一样。
我们也在推进量子运算。虽然目前仍处于称为杂讯中尺度量子阶段 (NISQ,Noisy Intermediate Scale Quantum Computing),但已有许多有潜力的应用开始浮现。我们正在研发一个量子与GPU混合的运算平台,称为 CUDA-Q,与全球许多很棒的公司携手合作。GPU 可用于前处理与后处理、错误修正与控制。未来我预测,所有超级电脑都会具有量子加速器(QPU),与 GPU 和 CPU 一同构成一个现代化的超级运算系统。
AI是通用的翻译机
12 年前,我们从感知型 AI 开始,AI能够识别语音、图像与模式,这是起点。过去五年,我们进入了 生成式 AI(Generative AI),AI 不仅能理解,还能创造。它可以从文字产生文字,我们在ChatGPT很常见,也可以从文字产生图像、影片,反过来也可以。也就是说,它可以将任何形式的资料转换为另一种形式,这正是我们所说的AI的优点:,亦即一种通用的转译器,可以将任何形式的资料转译成另一个形式,只要能将资讯用Token来呈现,就能让AI转译与推理。
现在,我们来到更进一步、更重要的阶段:生成式AI让我们体验了具备一次学习能力的人工智慧系统(One-shot AI),可以跟你一问一答,两年前我们与ChatGPT的相遇使我们感到惊艳与突破,你打字、他回覆,并且预测下一段文字。然而所谓,应该不只是从大量资料中学习,而是应该要有推论能力,能够解决未曾见过的难题。能够把複杂问题逐步拆解,甚至或许运用逻辑与定理去解决没遇过的难题,甚至能模拟多种选择并分析其利弊。或许你听过一种科技叫做让AI拆解问题;则是让AI列出许多方法途径,这些都让AI拥有了。
明年会是数位机器人的重要时代
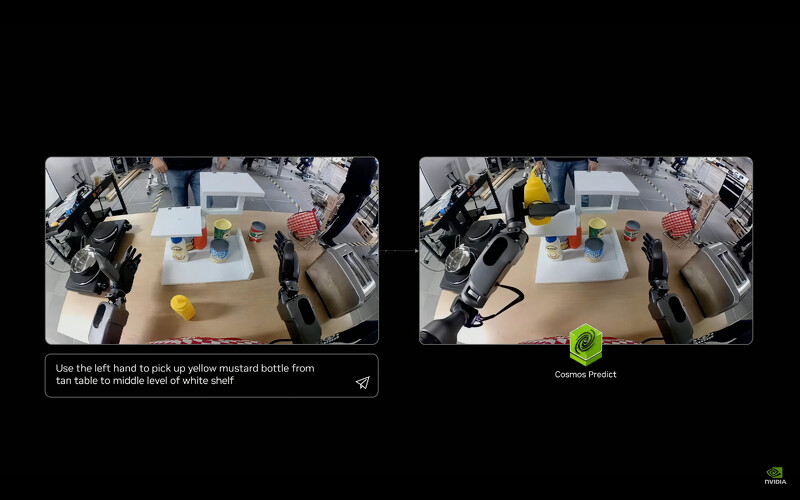
当 AI 能够推理,并结合多模态理解,像是阅读 PDF、搜寻、使用工具等,它就成为。这种 AI 就像人类:理解任务 → 拆解步骤 → 推理决策 → 执行行动。我们人类会考虑后果,并且执行计画。这种代理AI可以研究、使用工具、与其他 AI 协作。也就是说,Agentic AI 是能理解、思考并採取行动的AI。这正是机器人(robotics)的回路,Agentic AI 基本上就是数位形式的机器人。明年会是重要的一年,我们将会看到在这个领域有许多进展。
而下一波则是,它能理解现实世界的物理定律,例如惯性、摩擦力、因果关係。当我滚一颗球到车子下方,它会知道依照球的速度,球会从车子的另一侧出现,它能理解(Object Permanence),球不会在车下消失;如果有一张桌子在你面前,当你要去另一端,它能推论最好的选择不是撞向桌子,而是绕过桌子或是从桌子底下通过会更合理。要能理解这些物理性原则,才能通往下一个阶段。我们称为,你可以看见这类 AI 能生成影片来训练自动驾驶的车辆等各种场景,例如加入鸟、人、狗等变数 。

AI能生成影像就能捡起瓶子
下一步,我们将这些推理系统、生成系统与实体理解能力,全部结合进一个实体载具,也就成为了。如果你能用文字下指令要求AI,那么你可以想像能够对机器人下达的指令,现今的 AI 技术已经具备这样的能力。
为了实现这一点,我们打造了一种全新的电脑架构,叫做Hopper,三年前问世,彻底改变了 AI 运算方式,成为全球最知名的电脑之一。这几年我们又开发了一款新系统,想要进行,基本上就是指用非常快的速度思考。你可以想成当你在思考的时候,其实脑中生成了大量的Token,而你在脑中反覆运算后,输出了最终的答案。因为想让AI从单次输出(one-shot AI)进展成思考型 AI(thinking AI)、推理型 AI,都需要非常大量的计算力,为此我们开发了最新的Grace Blackwell 系统。
Grace Blackwell具有几项功能,它能—— 将一台电脑变成一台巨型电脑。这与—— 将任务分配至多台电脑不同。向外扩展容易,向上扩展非常困难,尤其是已接近半导体物理极限,而Grace Blackwell做到了,它几乎突破了所有限制,很多伙伴正在与我们合作构建 Grace Blackwell 系统。现在它已全面量产,儘管这过程异常艰难。基于HGX架构的 Blackwell系统,从去年底已开始量产,自今年二月起开放使用,如今全球每一天都在各个角落快速上线中,各地的CSP(云端服务供应商)都已导入,推特上也有许多人发表Grace Blackwell相关讯息。而正如我承诺每年都要优化平台,今年第三季我们将升级至Grace Blackwell GB300。仍然是相同架构、相同外型与机械构造设计,但内部晶片升级了,包括推理效能提升1.5倍、高频宽记忆体(HBM)提升 1.5 倍、网路连接提升2倍等,可说是整体系统效能全面提升。记得我说过吗?NVIDIA 在近十年内将AI运算能力提升了大约一百万倍,而我们仍然维持进度。要做到这些并非将晶片做得快一点就可以,因为晶片的速度和大小有其限制。而Grace Blackwell可以将晶片连结在一起。Grace Blackwell 的计算节点已全面改良,从上一代的B200到B300,外观一致,可插入相同的机柜与底座,这就是Grace Blackwell的伟大之处。

NVIDIA建造的东西都很巨大,原因是我们并非在做资料中心或伺服器,我们是在建构AI工厂。这些系统动辄花费400亿、500亿,因此是非常鉅额的工厂投资,但你们都明白为什么:,工厂就是这个道理。
科技非常複杂,光看这些,你可能还是无法充分感受到我们在台湾的伙伴公司的贡献,这些非常精彩,而且都是你们做到的。今日的台湾不只是为了世界生产超级电脑,我很高兴地宣布,我们也正在为台湾建造AI,我们正式宣布,鸿海、台湾政府、台积电、与NVIDIA将为台湾打造第一台超级电脑,用来建构AI基础建设与AI生态圈。
每一位学生、研究员、科学家、新创公司、大型企业,像是台积电早已建构了大量的AI与科学研究,鸿海在机器人领域贡献良多,我知道坐在观众席中有许多人都在AI、机器人领域有所研究,因此拥有世界级的AI基础建设对台湾来说是非常重要的。
这一代的NVLink和Blackwell使我们能够创造这个强大的系统,一个巨型的晶片,这里有 Pegatron(和碁)、QCT(云达)、Wishtron(纬颖)、WeWin 等公司所做的系统,包括 Foxconn(鸿海)、Gigabyte(技嘉)、ASUS(华硕)等150家公司耗费三年来打造的成果,以及其中的软硬体,这都是巨大的产业投资。

NVLink Fusion的半客製化计画
而今天我们希望所有想打造资料中心的人都能做到,我们将发表一项特别的NVLink Fusion计画,以此可做出半客製化的AI基础建设,并不只是半客製晶片,那已经是过去的做法。每个人都想要AI基础建设,但每个人想要的可能都有点不同,要做到很困难,NVLink晶片就是关键。NVLink 能让你将这些半客製系统扩展成真正强大的电脑,你能够混搭整个系统,甚至可以使用客製化的ASICs晶片,你同样可以整合进我们的超级电脑生态系统。你的AI架构可以部分使用 NVIDIA,也可以大部分是你自己的。你依然能够享有 NVLink 和 SpectrumX 带来的连结性与扩展性,以及背后庞大产业生态系的稳定性。这就是 NVLink Fusion。
如果你所有东西都买NVIDIA,我当然很高兴;但如果你只有部分东西买NVIDIA,我会欣喜若狂。
我们现在有以下重要合作伙伴:Alchip、Astera Labs、Marvell、联发科(MediaTek):他们会协助客户打造自己的 ASIC或是半客製化系统。富士通(Fujitsu)、高通(Qualcomm):正在打造支援 NVLink 的 CPU。Cadence 和 Synopsys:我们和他们合作,将 IP 授权给他们,以便你们都能使用这些技术来建构晶片。
你的桌上型超级电脑
这是个令人惊叹的生态系,这只是 NVLink Fusion 生态的一部分亮点。一旦与这些伙伴合作,你就能被整合进更大的 NVIDIA 生态系中,让你能建构自己的 AI 超级电脑。
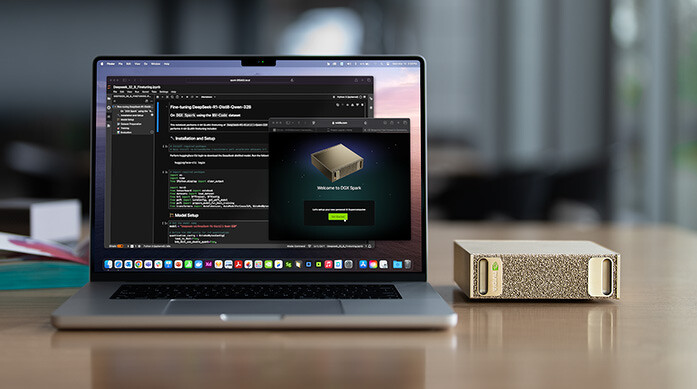
现在我来谈谈一些新的产品。你刚刚看到我展示几款不同的电脑,但为了满足世界上更广泛的需求,还有一些电脑我们需要补上。首先,我要告诉大家一个更新:我们的 DGX Spark 已经全面进入量产。几週后就会上市。合作伙伴包括:Dell、HPI(惠普)、ASUS、MSI、Gigabyte、Lenovo 等等,这就是DGX Spark。这其实是我们的量产机型,我们的合作伙伴也会推出他们不同的版本。这是为 AI 原生开发者设计的电脑:如果你是开发者、学生、研究人员;你不想每次开云端、用完再关,你想要有一台永远开机、专属你用的个人AI云端电脑,这台就是为你打造的。你可以用来做原型设计、早期开发,回顾2016年的DGX-1,重 300 磅(大约 136 公斤),我根本没办法拿起来,效能达到每秒1千兆次浮点运算、128GB HBM。而今天这台DGX Spark,128GB LPDDR5X,效能其实是很相似的,但更棒的是,你能做的工作,跟在大型电脑DGX上能做的工作是一样的。这是十年来惊人的成就。我们的合作伙伴将自行定价,但可以确定的是:大家今年圣诞节都能拥有一台。

DGX Station:墙上插座能使用的极限
如果你觉得还不够大,还想要自己的个人超级电脑,这是另一台桌上型超级电脑,Dell、HPI、ASUS、Gigabyte、MSI、Lenovo 都会推出,也会由Box和 Lambda 等工作站品牌贩售,这台就是你个人的DGX超级电脑,这是你能从墙上的插座获得的最强运算效能。我想你可以把它放在厨房,但有点勉强,因为如果有人使用微波炉,可能就会跳电,这就是极限,这台是你墙上插座所能使用的极限了,这台是DGX Station。他的程式设计系统和我方才展示的巨大电脑是一样的,这是最棒的事,一台架构就具有足够的容量和效能可运作一兆参数的AI模型。
这些系统都是以AI为核心建构的系统,是为了软体世代建构的电脑,不需要相容x86架构,也不需要能够运作传统的IT软体,不需要能够运作虚拟化管理程式(Hypervisor),也不需要能够使用Windows系统。这些电脑是为了现代AI应用程式打造的,当然这些AI应用程式也可以封装为 API(Application Programming Interface),供其他传统应用程式系统调用。但为了让我们带AI进入崭新的世界,我们得回到根源,我们得革新运算方式,将人工智慧引入传统企业运算环境。传统产业的运算环境就我们所知,大概就是三个层级,运算、储存、网路,AI的导入肯定会改变产业IT。它必须能够和产业IT共同运作,并且增加新的功能,对产业来说,具备新功能的就是代理AI。

代理AI就是数位员工
数位行销活动经理、数位研究员、数位软体工程师、数位客服、数位晶片设计师、数位供应链经理等等,基本上就是我们以往工作的数位AI版本,正如我先前提到的,代理AI具有推理能力,能使用工具,并且与其他AI协作,所以从各方面来讲,它们都是数位工作者,是数位员工。世界正缺乏劳动力,劳工短缺,到2030年我们将短缺3000万至5000万的人力,这其实限制了世界的成长,现在我们有了数位员工能够一起工作。100%的NVDIA软体工程师现在已有数位代理AI跟他们一起工作,帮助他们研发更好的编码并且有更好的生产力。我们的愿景就是在未来,产业IT中会有一个新的层级是代理AI。
这世界会发生什么事?企业会发生什么?我们有给人类员工的人力资源部门,而IT部门就是数位员工的HR。因此我们必须发展所需的工具让IT使用,让IT具有管理、提升和评估数位员工工作的能力,这是我们未来要研发的。但如前所述,我们得先重新定义演算方法,产业IT使用的是相容x86架构的传统电脑、跑的是传统的软体,使用的可能是来自VMware、IBM Red Hat、Nutanix的虚拟化管理程式,使用大量的传统应用程式,但我们将会需要能够处理这些事情的电脑,同时要具备的新功能。

所有工作都能驾驭的企业级伺服器
这是全新的RTX Pro 企业级 Omniverse 伺服器(RTX Pro Enterprise Omniverse Server),它能够解决一切问题。它当然有x86架构,可以运作所有经典的虚拟化管理程式,它使用kubernetes容器管理系统,当IT想要管理网路、管理所有丛集、自动化部署编排工作量,都可以像以前那样操作,几乎世上使用的所有东西都能在这里运作。不仅如此,它也是为了产业AI代理所设置的电脑。代理AI不只能够用文字呈现,也可以是电脑图像,就像Toy Jensen那样。AI代理员工可以是文字形式,也可以是图像,也可以是影像,所有的工作都可以在这台电脑里运作。所有这世上的模组、应用程式,都可以在这台电脑使用。它可以快速运算每秒产出的Token,但因为每个代理AI的工作不同,有些需要更多的推理能力,因此你必须算出每位使用者、每秒产出的Token产量,而且越高代表成效越好。而身为工厂需要高产能或低延迟,虽然不需总是两者兼顾,但挑战就是如何创造一个能够尽可能提高产能、降低延迟的运算系统。
RTX Pro 企业级 Omniverse 伺服器能运用不同方式来提高产能、降低延迟。世界最知名的电脑Hopper H100,$225,000。这台RTX Pro 企业级 Omniverse 伺服器,具有Blackwall系统1.7倍的效能,更棒的是它是DeepSeek R1。DeepSeek R1是给世界的礼物,是一大突破,也开启后续许多很棒的研究,我去世界各地,都看到DeepSeek R1是如何影响人们思考AI以及模拟和推理能力,他们真的对这世界和产业有极大的贡献。DeepSeek R1成效表现是H100的4倍,所以如果你想要建构产业AI,我们有非常好的伺服器和系统可以提供给你。你可以在这电脑上运作所有的东西,有非常好的成效,而且能够兼顾x86和AI。RTX Pro 企业级 Omniverse 伺服器已经在大量生产中,这可能会是我们有史以来最大规模的上市计画。
Vast整合AI搜寻
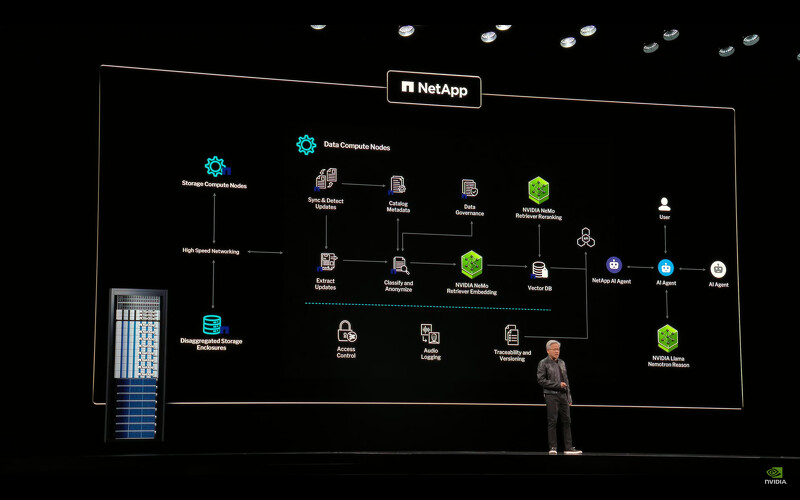
演算平台改变,储存平台也不同。原因是人类倾向查询像是SQL这类结构化资料库,但AI倾向查询非结构化的资料库,他们想要语意和意义,所以我们需要创造一个全新的储存平台,而这是NVDIA AI数据平台,上层正如SQL伺服器、软体,以及厂商提供的储存系统,如你所知,大多数提供储存系统的公司都是软体公司,这一层软体非常複杂,所以这种新型储存系统,会有一个我们称之为 iQ 的新查询系统,NVIDIA AiQ 或 iQ,这真的是最先进的,并且与储存产业几乎所有人合作。未来你的存储不再是CPU,而是搭载GPU的储存空间。原因是你会需要这个系统嵌入并且在非结构化、原始数据中索引、搜索和排序,这个过程需要大量计算的资源,所以未来大多数存储伺服器将会在前面配备一个GPU 计算节点。这一切都奠基在我们创造的AI模型之上。
我们创造AI模型,并且灌注大量精力与科技在OpenAI模型的后训练处理,我们后训练这些模型,资料都是公开透明化的,都是安全公开的清单让大家都可见,而我们后训练模型的成效是非常惊人的,现在可下载的公开来源具有推理逻辑的AI模型中,Llama Nemotron模型是最强大的,下载次数非常可观,而我们也让利用AI搜寻的功能,比市面上所有AI搜寻都快了15倍,而且有50%的机率是更好的搜寻结果。这些都是公开的蓝图,而且我们与储存业者合作,整合这些AI模型到储存平台中的AI系统,我们称为。

Dell拥有强大的AI平台,是世上具领导地位的储存厂商,Hitachi有着强大的AI平台、IBM使用NVIDIA的Nemo建构AI资料平台,NetApp正在建构网路资料平台,你可以看到这些资料全都公开透明,如果你正在建构一个使用语意查询的AI平台,NVIDIA Nemo是世上最棒的。
智能IT运营将进入市场
接下来是关于新的软体,我们称为AIOps(智能 IT 运营,Artificial Intelligence for IT Operations)。正当供应链和HR都有他们自己的运营软体,未来IT也会有自己的运营软体,它们会整理数据、微调模型,他们会评估模型、设置护栏模型,我们也有许多程式库和模型将会整合进入AI运营生态圈。我们有很棒的伙伴帮助我们做这些事,并且协助进入市场,CROWDSTRIKE、DataIQ、DataRobot都正与我们合作。你可以看见,这些 AI 运营操作,包括建立微调模型与部署模型,都是用于企业使用的代理AI(Agentic AI),而你也可以看见NVIDIA的程式库与模型都无所不在。elastic我好像听说已经被下载了4000亿次。还有NUTANIX、Red Hat,以及台湾的趋势科技,Weights and Biases等,这就是我们将如何让产业IT拥有让AI做各种工作的能力。我们可以在原有的功能上加入AI,如今藉由包括Dell等很棒的伙伴们协助,我们有了能够让企业做好準备的系统,我们将把这些平台带给全世界的产业IT。
接下来我们谈谈机器人。代理AI你可以有很多种叫法,但基本上他就是数位机器人,因为机器人就是可以感知、理解并且策划行动,而这就是代理AI做的事情。但我们也会想要建构实体机器人,但实体机器人的前提就是它必须要有能够学习当机器人的能力。但学习当机器人的能力无法在实体世界有效地执行,你必须创造一个虚拟世界让机器人在那能够学习当一个好机器人。在那个虚拟世界必须遵照物理原则,大多数虚拟世界使用的物理引擎,在处理刚体和软物体时没有拟真的能力,因此我们和Google DeepMind和迪士尼研究部门(DisneyReserch)合作打造了世界最棒的物理引擎(牛顿),它会在7月开放原始码释出。它完全使用GPU动能,能做到很不可思议的事。它是可微分的(differentiable),变化率是可计算的,因此能够从经验中学习,具有高拟真度,且非常即时,它也被整合到机器人用物理函式库MuJoCo以及NVIDIA的Isaac Sim模拟平台,因此不论你使用的模拟环境和框架是什么,我们可以藉此让机器人成真。

实体机器人成为事实
你能想像这些小机器人在你家跑来跑去,追逐你家的小狗并且把牠们惹毛吗?你看到的这不是动画,是模拟画面,画面中的机器人在沙子里滑行,所有一切都是模拟画面,机器人的软体正在运作模拟机制。所以在未来,我们会将训练好的模型让实体机器人模拟,让他们学习如何当一个好机器人。我们正在做一些事情协助机器人产业,你们都知道我们已经着手自动化系统有一段时间,像是自驾车我们基本上就有三个系统,有创造AI模型的系统,GB 200、GB 300就是用在训练AI模型。然后也有Omniverse去模拟AI模型,然后当你训练完AI模型,你得把AI模型放入车里,我们今年就在世界各地的宾士车中部署了我们的自驾车软体组合。我们创造了完整技术,然后开放技术,我们的伙伴能够随心所欲地使用,他们可以用电脑但不用程式库,也可以用完电脑与程式库后还使用我们的执行程序,怎么使用都取决于你自己。但我们希望能够让大家尽可能方便地整合运用NVIDIA的技术。就像我前面说的,我当然喜欢你什么都从我这里买,但如果你只买一部分那会更好,我很实际。
所以我们也在机器人产业做相同的事情,就像自驾车一样。这是Isaac GR00T平台(开放式机器人开发平台),模拟器就跟Omniverse一样,训练系统也是一样的,当你训练完AI模型,你就放到Isaac GR00T平台,这个平台使用的是全新的电脑Jetson Thor,这是一个非常惊人的处理器,而且正要开始生产。基本上机器人处理器是用在训练自驾车,也可以用在导入人类或机器人系统上,它的运行系统是NVIDIA Isaac,常被运用在神经元网路处理、感测器和管线处理流程,然后产出最终的结果。我们今天在此宣告Isaac GR00T N1.5已经正式开放,全世界都可用,而且已经被下载了6000次之多,也受到大家的喜爱和讚赏。

用AI教AI当个好机器人
除了创造模型外,我们也告诉大家我们创造模型的方法,在机器人或说整个AI产业最大的挑战就是你的资料库策略,那通常是大量的技术和研究所在,在机器人产业,我们教机器人就像教自己的小孩,或像是教练示範给运动员看,你用远端遥控的方式告诉机器人如何执行任务,机器人能够(Generalization),AI有能力从展示中学习,甚至从一次示範中学到其他的方法技巧。那么如果你想要教机器完整的技巧,那将会需要多少人员?当然会非常多。所以我们想做的是利用AI来强化人类的示範系统,所以这是从现实到现实,只是利用AI去扩大且强化人类示範时所蒐集到的资料数量,再用来训练AI模型。所以,想要让机器人变成事实,你就需要AI。而为了训练AI,你更需要AI。值得庆幸的是,虽然我们需要大量人工生成资料,但我们刚好处在一个AI代理的世代。机器人需要大量人工生成的资料,微调也需要经由大量的强化学习,以及鉅额的运算,这是一个需要大量运算的世代,来训练AI、发展AI以及使用AI。就像先前提过的,世界劳工短缺,这也是为什么实体机器人如此重要的原因之一,这是唯一一种几乎能够在各种恶劣状况都能部署的机器人类型。它们能够融入我们创造的各种世界,可以完成我们自己的任务。我们为自己开创了一个世界,现在我们可以设计出能融入这个世界的机器人来协助我们。

数位双胞胎让机器人学习共事
另一项很棒的事情是,如果机器人真的成真,他们会多才多艺,而且也可能会是最成功的机器人,因为每项科技都需要规模,我们现有的其他机器人都是少量的,因此永远无法达到会成为科技巨轮的规模,发展得不够快、不够长远,我们就不会愿意投注技术来使它更好。但实体机器人很有可能会成为下一个数以兆元的产业,科技创新速度会非常快,对运算和资料中心的需求量会非常的大。不过这会是需要三种电脑的应用,一是AI学习,二是模拟引擎,让AI在虚拟环境学习当一个机器人。三是用来部署。任何会动的东西都可以是机器人,当我们将机器人放入工厂,请记得,工厂本身也是机械化。现在的工厂是惊人地複杂,画面上是Delta的生产线,而他们已经準备好未来要启用机器人。工作过程已经是机械化并且以软体定义,未来将会有真的机器人在里面工作。
为了让我们能够创造且设计出能够像是团队合作的机器人,我们必须利用Omniverse让他们学习共事。你将会有一个数位双胞胎,所有的设备也会有数位双胞胎,你会有一个数位双胞胎工厂。这就是Omniverse能够做的训练。如果你以为这是照片,其实这也是模拟画面,也是一种数位双胞胎。此时,一项高达五兆元的厂房正在世界各地规划中,在接下来的三年内,世界正在重塑,各地正在重新工业化,到处都在盖新厂房,这对我们来说是很好的机会,将所有的东西都交由数位双胞胎来执行,会是迎接机器人未来的第一步。这还不包含我们即将建构的新型态工厂,而且就连我们自己的工厂,我们也使用了数位双胞胎。NVIDIA有数位双胞胎,就连高雄也有数位双胞胎。

台湾将会迎来重大商机
我整篇演讲都在讲在座各位的成就,台湾身为产业的中心,也将会是未来许多AI和机器人的产地,这是台湾的好机会,也将会是世界最大的电子製造地区,因此AI和机器人会转型为我们要做的事。所以这会是史上第一次,你做的事情将对所有产业造成革命性的影响,而最终也将对你的工作产生革新。你将AI带来这世界,现在AI要来革新你做的所有事情。

NVIDIA办公室落脚北投士林
最后我还有一个新产品要宣布,大家都知道我们持续成长,与伙伴们的合作也持续成长,我们在台湾的工程师数量也持续成长,已经突破了现有的办公室容量,所以我要为他们建造一座NVIDIA台湾办公室,叫做NVIDIA CONSTELLATION,我们一直在挑选地点,所有的市长和城市都对我们很好,我想我应该获得一个很好的交易,不过我不太确定,因为也满昂贵的,不过毕竟是黄金地段,今天我很高兴宣布,NVIDIA CONSTELLATION会在北投士林。我们经由协商,才从现有的地主手中取得租约,然而据我所知,要让市长核准这份租约,他需要知道台北市民都同意我们建造巨大美丽的NVIDIA CONSTELLATION,他也要求大家打电话告诉他,所以我相信你们都有他的电话,请告诉他大家都觉得这是个好主意。我们会尽快开始建造NVIDIA CONSTELLATION,因为我们需要办公空间。NVIDIA CONSTELLATION北投士林,令人振奋!

我要感谢大家一直相伴,这将是我们一生一次的重大机会,这绝非轻描淡写,在我们眼前的机会将会超乎寻常。我们正在创造IT的下一个世代,其实我们不是第一次这么做,从PC到网路,到云端、行动云端,这次我们不只是再创在IT的新时代,我们更是在创造一个全新的产业。这个全新的产业,将让我们接触巨大的商机。期待未来在各种领域与各位合作,祝你们有个很棒的Computex。
黄仁勋 COMPUTEX 2025 演讲全文
延伸阅读:
黄仁勋宣布辉达台湾总部在,未来将打造AI超级电脑黄仁勋也是细节控?抵台的穿搭造型亮点是Richard Mille腕錶!黄仁勋美食地图再+1!怀旧台菜餐厅举办兆元宴,必吃推荐菜色一次看 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏


