Claude Opus 4.1 has been released, bringing several improvements and new features for software developers. Here are some of the key updates:
1. "Enhanced Performance": The latest version offers improved speed and efficiency, allowing developers to handle more complex tasks with greater ease.
2. "New API Endpoints": Additional API endpoints have been introduced to provide more flexibility and functionality, enabling developers to integrate Claude Opus 4.1 into their applications more seamlessly.
3. "Improved Natural Language Understanding": The model now has better natural language processing capabilities, making it more accurate and responsive to developer queries and commands.
4. "Expanded Knowledge Base": Claude Opus 4.1 has been updated with the latest information, ensuring that developers have access to the most current and relevant data.
5. "Enhanced Security Features": New security measures have been implemented to protect sensitive data and ensure that developers can work with confidence.
6. "Better Collaboration Tools": Improved collaboration features allow multiple developers to work together more effectively, streamlining the development process.
7. "Customization Options": Developers can now customize the model to better suit their specific needs, including the ability to fine-tune parameters for optimal performance.
8. "Debugging and Error Handling": Enhanced debugging tools and improved error handling make it easier for developers to identify and resolve issues quickly.
If you have any specific questions or need further details about any of these features, feel free to ask!
相关内容:
作者 | Hien Luu
译者 | 田橙
Anthropic 已推出 Claude Opus 4.1,这是针对 Opus 4 的重要升级版,显著增强了模型在多文件项目中的代码可靠性,并提升了模型在长链式交互中的推理能力。该版本在 SWE-bench Verified 基准测试 中的得分由 72.5% 改进至 74.5%,说明模型在真实世界编程任务中更加可靠。
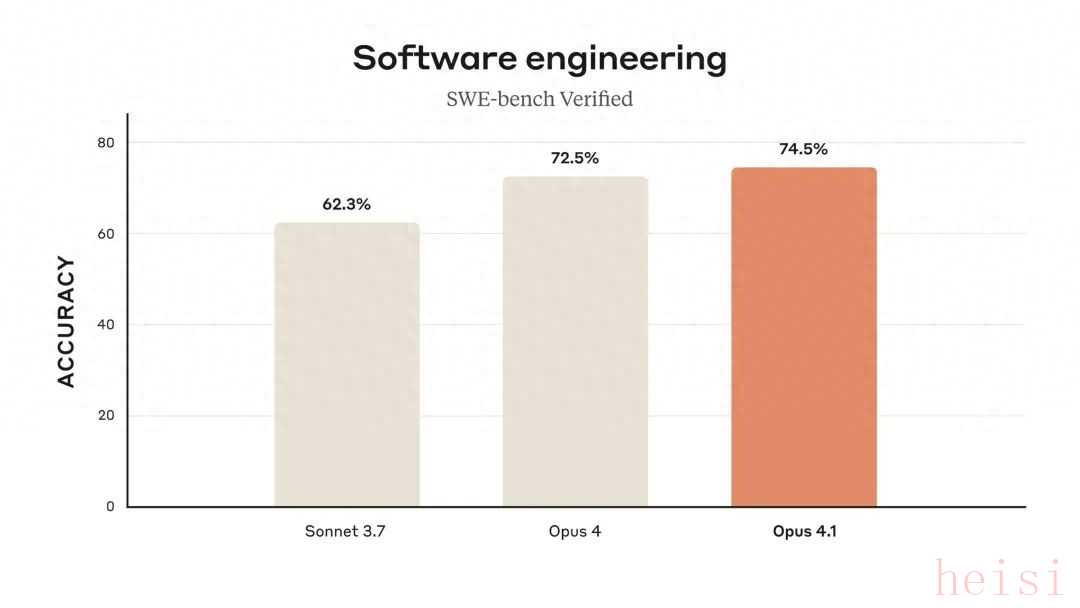
图 1:Opus 4.1 与 Opus 4 在 SWE-bench Verified 准确率上的对比
在 Opus 4 的基础上,新版本进一步强化了 Claude 作为编程助手的能力,尤其在开发者常用的多文件场景中,其代码重构的可靠性有了提升——这是许多 AI 助手的薄弱环节。Anthropic 还指出,模型在长时间交互中跟踪推理链和状态的能力有所提升,这对类代理(agent-like)工作流程至关重要。他们将这些更新视为循序渐进但意义显著的改进,助力 Claude 向更实用、可应用于企业级场景的 AI 助手发展。
SWE-bench Verified 被广泛认为是衡量编码助手在真实 GitHub 项目中解决问题能力的重要基准测试。相比于合成基准,SWE-bench 更贴近真实开发场景,因此其得分提升被视为模型在实际编程任务中能力增强的重要指标。
据发布说明所述,GitHub 反馈称 Opus 4.1 在复杂重构任务上性能更强;Rakuten Group 表示,Claude 能在大型代码库中准确指出修正位置,且不会引入无关改动;而 Windsurf 在内部面向初级开发者的基准测试中,观察到比 Opus 4 高出一个标准差的性能跃升——这一跨越被比作从 Sonnet 3.7 升级到 Sonnet 4 的提升。
安全性方面,Claude Opus 4.1 的“无害响应率”(harmless response rate)提升至 98.76%,相比 Opus 4 的 97.27% 有明显提高。这意味着模型在拒绝违规请求时更加可靠。同时,在涉及武器或毒品合成等高风险滥用场景中,模型的合作率下降了 25%,有效降低企业在合规与品牌方面的风险。
“无害响应率”是衡量模型在对抗违禁或危险内容请求时保持安全响应的一项核心指标,尤其对企业部署而言,这关系到合规性与品牌形象。
Claude Opus 4.1 目前已向以下用户开放使用:已付费的 Claude 用户、通过 Claude Code 用于终端工作流的用户,以及通过 API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 平台接入者。值得一提的是,其定价保持与 Opus 4 相同。
原文链接:
https://www.infoq.com/news/2025/08/anthropic-claude-opus-4-1/
声明:本文为 InfoQ 翻译,未经许可禁止转载。
今日好文推荐
叮!极客邦 2025 秋招“通关文牒”已送达!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏


