这个说法很有趣,也确实引起了广泛的讨论。根据2023年10月OpenAI发布的一份内部测试报告,结果确实显示"Anthropic开发的AI模型Claude在“指令遵循能力”(Instruction Following)方面超过了OpenAI的ChatGPT"。
这并不是说Claude在所有方面都比ChatGPT强,或者它是一个完美的AI,而是特指在理解和执行复杂指令方面的能力上,Claude在这次特定的、由OpenAI进行的内部测试中表现更优。
"需要强调几点:"
1. "测试的特定性:" 这只是OpenAI内部进行的一次测试,测试的侧重点和范围是有限的,不能完全代表AI能力的全部。
2. "“最强”的定义:" “最强”是一个很主观的概念。在不同的任务、不同的评估标准下,结果可能会完全不同。例如,在创造力、代码生成、知识广度等方面,ChatGPT目前仍然具有很强的竞争力。
3. "AI发展的快速性:" AI领域发展日新月异,今天的测试结果不代表明天的情况。各个公司都在快速迭代和改进他们的模型。
4. "测试的目的:" OpenAI进行这样的测试,可能也是为了更客观地了解竞争对手,促进自身模型的进步,而不是单纯地为了证明谁“最强”。
"总结来说:"
OpenAI的内部测试确实显示了Claude在指令遵循方面表现优异,超越了ChatGPT。但这更像是一个技术指标
相关内容:
Claude把GPT-5按在地上摩擦,OpenAI自己盖章认证。
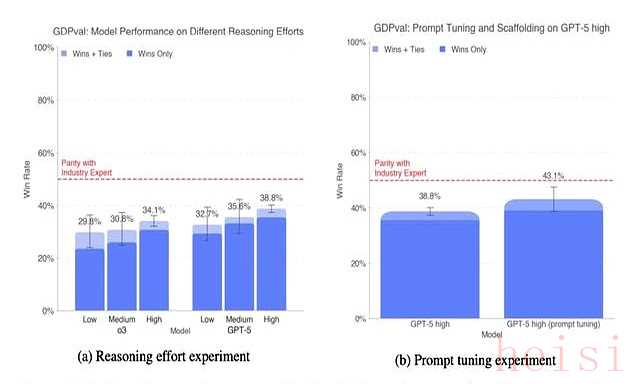
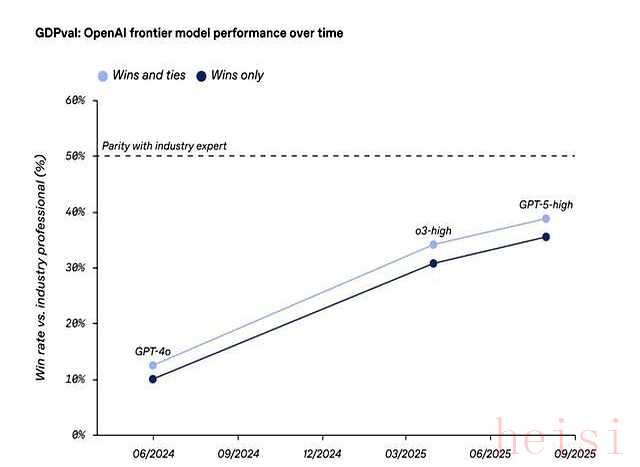
GDPval榜单刚放出来,围观群众全傻眼:第一名不是亲儿子GPT-5,而是Anthropic家的ClaudeOpus 4.1,胜率47.6%,直接甩开GPT-5八个身位。
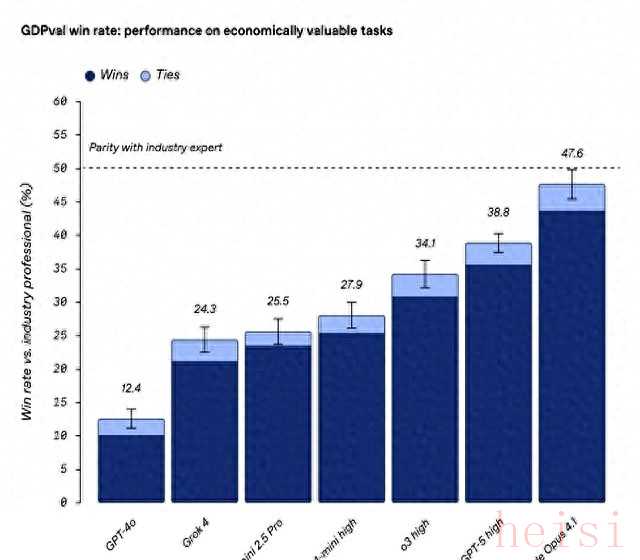
测试任务很现实:44种高薪工种,3万亿美元年产值,做PPT、写财报、给病人排诊疗方案,全是老板明天就要的急活。
人类专家当裁判,谁做得快、做得顺眼、做得不用返工,谁拿高分。
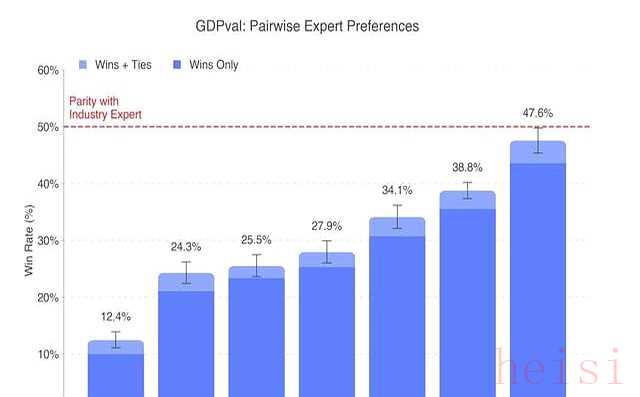
Claude赢在外观。
一份路演PPT,它自动把图表颜色调成客户品牌色,字体间距像专业设计师手调,评委顺手就给过。
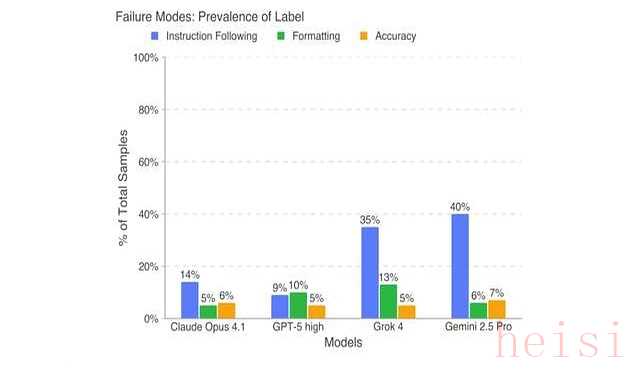
GPT-5输在内敛,数据再准,页面丑,照样被打回重做。
OpenAI研究员在报告末尾补了一句:GPT-5准确率更高,但市场首先为颜值买单。
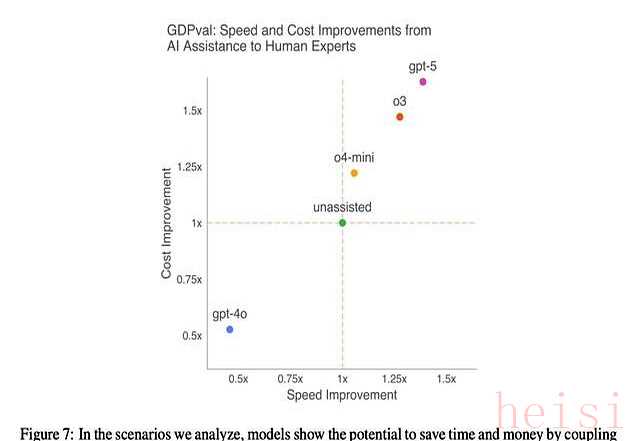
话很委婉,翻译过来就是——用户懒得看细节,先看顺眼程度。
Anthropic工程师后来透露,他们在训练里塞了120万份高分简历、融资BP、品牌手册,让模型把排版刻进骨头。
GPT系列喂的是论文和代码,天生对对齐像素点没兴趣。
微软动作最快,已经悄悄把Claude塞进PowerPoint Designer。

下个月更新完,Office用户点一下,Claude帮你把满页文字变成高颜值图示,GPT-5负责藏在后台查错。
两套模型一起打工,费用却按一份收,微软算盘打得精。
有人高兴就有人慌。
自由接单做PPT的设计师,单价从一页200跌到80,客户直接甩AI图:照这个抄,今晚给我。

再不做模板库,你会损失整月订单;不懂这招,下一个被替代的就是你。
榜单之外,GDPval也被扒皮:只测美国44种职业,一次交稿完事,没给修改机会。

真实职场要来回沟通、拉群开会、背锅改稿,AI能不能扛住还得打问号。
MIT实验室连夜补测,让模型多轮返工,Claude胜率跌到39%,GPT-5升到42%。

结论简单:一次出图Claude封神,长期迭代GPT-5更稳。
选谁,看你公司节奏。
短期靠颜值吃饭的人,先把Claude模板抄走,无脑复制,明天就用这三句话:标题用无衬线,色块用品牌色,留白别手软。
长期靠精度吃饭的人,把GPT-5接进后台,数据让它算,错一个标点都算我输。

AI圈没有永远的王,只有不断换座的客人。
今天Claude坐上头把交椅,明天GPT-5带新皮肤杀回来。
唯一确定的是,还在手动改格式的打工人,时间窗口真的不多了。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏


